Minimum RISC-V System From Scratch¶
So, we’ll make a RISC-V system! It may sound “mission impossible” to build this kind of thing from scratch in a relatively short time, without prior background in hardware designs. But it really isn’t as magical as it seems. I hope this tutorial could serve as a tiny but inspiring guide to those programmers who know little about hardware like I did to have a better understanding of how a computer system works from the ground up, and for those who know a bit about different pieces of the story but can’t put them together.
Nothing is better than having a playable example that is both small and functional. This repo already contains a RISC-V processor core implementation that is synthesizable by itself, but also directly works with a minimal emulator (Verilator-based) code with a realistic system setup. The processor implements RV32I instruction set with major part of CSR Mode-M, while the emulator emulates the cache/memory, serial console output, video output and keyboard input. The applications are built with standard gcc/Rust RISC-V toolchains and directly run on the processor.
The whole repo is simply divided into three parts:
Processor core implementation in SystemVerilog: core.sv (1.2K loc) and csr.sv (182 loc).
System emulator: sim.cpp (423 loc).
Example applications that directly runs on
sim:apps/*.candapps/mriscv-rs/examples/*.rs.
This tutorial is organized in two parts: the implementation of the processor core with SystemVerilog and the building of the final system/applications.
Make a RISC-V processor¶
What Makes a Processor?¶
A processor, like the name suggests, processes data via computation. More specifically, the prevailing modern computer processors adopt a computation model that is largely inspired by Turing Machine (as opposed to Lambda Calculus, which gave birth to functional programming languages). A typical processor has three main functions for its operation:
The ability of taking input data from the containing system and putting results back to it. (I/O)
The ability of processing the data, such as doing arithmetic or logical operations. (Computation)
The ability of maintaining an internal state, which could affect its behavior during processing. (State and Control)
Without any one of them, the construct sounds less “exciting”: without I/O, a processor makes no difference from a dummy blackbox that does nothing inside; without computation, the processor can only output data as-is; without being stateful, a processor is a simple calculator whose outputs are immediately determined by its inputs (which could be implemented solely by combinational logic circuits, which will be discussed soon) and the system won’t be stateful to control other things. Many mechanical systems are stateful, such as your wrist watch, which keeps track of the current time as the state and changes it as time ticks. In fact, a mechanical watch/clock is a computer/processor as it takes inputs (you can adjust the time and set the alarm), generates outputs (you can always check the time from the display), process the data (basic arithmetic to maintain the current time) and has state and control (triggers second/minute/hour hands according to its internal state) – it is just not a general-purpose computer. However, interesting mechanical computers do exist in history [link here].
Although the industry has been evolving its technology in the past decades, the
basic logic for a processor hasn’t been much different from its
theoretical model: like a Turning machine takes commands from a tape that
instructs its next operation, a CPU fetches the next instruction from a
(logically or physically) continuous portion of memory (or from the cache). It
also changes its internal state by the instruction like the Turning machine can
modify its state register. However, when it comes to details, the processor
architectures may differ in how they manage/layout their internal/external
states or how they interpret the instructions. Here we choose RISC-V as our target Instruction Set Architecture
(ISA) for our processor build. RISC-V is register-based, meaning all
temporary values are kept by registers in a register file, like lockers in a
locker room, individually indexed by names (x0-x31 in RV32). They’re directly
accessible, unlike stack-based alternatives which usually have to push to/pop from
a stack of values by their operations.
It is also a register-to-register (aka. load/store) architecture, where all
operations are done on the basis of registers, so that values have to be loaded
from the memory to registers before a computation and stored back to the
memory explicitly from registers afterwards, unlike many CISC architectures such as x86
which supports mixed use of values both from memory and registers (a register-memory
architecture).
With these basics in mind, obviously, we need to have different parts of the processor to take care of the three major functions. There should be a way to decode the instruction into some form of internal, temporary representation of its functionality, so as to control how the rest part of computation should be carried out. There should be some logic for doing the actual calculation, some organized internal “lockers” to hold the values and some logic to read/write the results from/to the main memory. Finally, there should be a loop-like logic to drive the entire composition of different parts, so the processor can move onto the next instruction and keep executing instructions one after another with full automation, like a machine gun.
Register Transfer Level Abstraction¶
It is not very hard to notice such a powerful construct could be implemented by repeatedly applying two kinds of “logic”:
the logic that is like a math expression, which calculates an “immediate” output (response) from the given input (signal) by pure, stateless logic operation,
the logic that “remembers” something, controlled by some external signal, which could be later altered or read out. (Like a “sequencer/synthesizer”, if you’re familiar with electronic music.)
In short, one gives us some math calculation, called combinational logic, while the other one introduces the notion of states, called sequential logic.
Indeed, in digital circuit design, there is a widely used abstraction that is based on this observation. Register Transfer Level (RTL) is used by languages like Verilog/SystemVerilog and VHDL to create a high-level schematics of logic circuits. It describes the logical behavior with these two kinds of logic as primitives, without having to dive too much into their low-level (gate-level) implementation. Each kind of logic usually has patterns and disciplines for its implementation and can be either automatically synthesized by specialized tools or hand-crafted if necessary (or both), while the RTL language can abstract this away so the design task can be divided into high-level logic design and low-level implementation (e.g. the use of basic gates and wiring/routing).
Combinational logic is usually implemented directly with the wiring of a cascade of basic logic gates (e.g. NAND/NOR gates). For a concrete example, a 2-input multiplexer (or simply “mux”) can be implemented as in the diagram:

Each component is a NAND gate where the output is the negation of a logical “and” of two inputs. With the shown wiring of four gates, the mux choses between inputs (I0 vs. I1) for the output switched by the control signal A. The value of I0 will be chosen (Q = I0) iff. A = 1.
As a comparison, in SystemVerilog (a popular RTL language), the mux can be implemented as:
// 2-input mux
module mux2(input i0, input i1, input a, output q);
// Combinational logic is a direct assignment to
// the wire from an expression.
// Since it is time-independent, the order of
// assignments does not matter (unlike many
// programming languages).
assign q = a ? i0 : i1;
endmodule
There is one thing that’s worth noting: the “calculation” here happens almost instantaneously as the underlying logic gates “maintain” their outputs from their inputs by physics (the use of semi-conductors). There is, however, still some time delay due to physical properties of the gates and the time for electrons to propagate on the wire or within the semi-conductors, at the scale of nano-seconds. Thus, the delay is largely affected by the depth gates wiring and complexity of the overall construction.
Sequential logic, however, is very different. Here we only discuss about synchronous sequential logic. As the main building block for such a logic, a flip-flop not only takes input as in combinational logic, but also requires a clock signal that drives it. In sequential logic, outputs are only stabilized and deemed as valid when the clock signal pulses (“rising edge”, going to 0 to 1; or “falling edge”, 1 to 0). The use of an additional clock signal effectively introduces the notion of time into the logic (unlike combinational logic, which is time-independent). The notion of discrete time also makes the changing state easy to reason about and manipulate. Interestingly, such seemingly “magical” building blocks can be still implemented by pure wiring of gates, to be stateful. The extra clock signal (or “reset signal”, for “latches”, its asynchronous counterpart) is the key ingredient that does the trick. The below diagram shows a wiring scheme for “D-type” flip-flop with NAND gates, which is a commonly used component in synthesizing sequential logic. In this flip-flop, the output (Q) will retain the “memorized” value, when the clock signal (Clk) is 0, and change to the input (D) when the clock is 1.

Sequential logic in SystemVerilog below may be synthesized/hand-crafted by a D-type flip flop.
module flip_flop(input d, input clk, output reg q);
// Sequential logic has notion of time.
// It can only be specified with in an `always*` block.
always_ff @ (posedge clk) begin
// Change the output only at
// the positive clock edge (clk = 1).
q <= d;
end
endmodule
Finally, consider the scenario where we combine both kinds of logic together: we wire the input of a combinational logic from the output of a D-type flip-flop, and then wire the combinational output to the flip-flop input. It creates a “loop” which takes the output from the current state and puts the new value to the next state after calculation, implementing an iterator whose iterations are driven by the clock signal.
module counter(input d, input rst, input clk, output reg q);
// A counter, whose value could be set to `d` when
// `rst` = 1 on the positive edge of `clk`, or increased
// by 1 when `rst` = 0 and clocked.
// combinational logic, a 2-input mux.
wire comb_result = rst ? d : (q + 1);
// sequential logic, to alter the state ("reg" for the
// register, wired to `q`)
always_ff @ (posedge clk) begin
q <= comb_result;
end
endmodule
Of course, the period of the clock signal (more precisely, the minimum gap between two clock cycles) should be conservatively chosen to be larger than the circuit time of the combinational logic, so the input to the flip-flop is stabilized before the next clock ticks. This also reveals why processors nowadays are “pipelined”, the topic of the next section.
Instruction Pipelining¶
There are many possible schemes for a processor design. The simplest idea is to utilze the “loop” we just talked about to mainly divide the processor into two parts:
Computation: this part can be built with a cascade of combinational logics that “generates” the result from the wire, as signals go through a series of gates. More specifically, it first decodes the instruction into data and control signals. Then it immediately wires the data into an Arithmetic Logic Unit (ALU). An ALU is built by a mux which selects the kind of calculation the instruction needs to perform, given the control signal. It may also use the operands from the register files, which is the current state of the underlying flip-flops. Overall, the next state for the processor is prepared in this giant fabric of purely combinational logic.
State Transition: the results from the computation logic are ephemeral, like the other end of an eletric wire. We thus would like a sequential logic that finally updates the processor’s state before the clock cycle ends. Usually such sequential logic is done together with the register file, which writes back the outcome of the execution to its flip-flops. The changed values will become available again at the beginning of the next cycle, when used again by the combinational logic by the computation.
The scheme is usually called a single cycle processor. The main advantage of choosing this scheme is that it is fairly easy to implement with limited number of gates and low complexity. It has many downsides, so few modern processors still use it. A major one is the processing throughput (e.g. instruction per sercond) equals to the clock frequency as the processor can exactly handle only one instruction per cycle. Whereas the choice for the clock cycle time is not arbitrary: like we previously said, the longest circuitry in the combinational logic for computation sets the lower-bound for the cycle time, which is not scalable for implementing a modern, realistic CPU, due to the complicated specification of the ISA. Even worse, the cache/memory access time during the computation can drag the cycle time even further, resulting in a low average frequency for the processor.
Nowadays, you would probably see builds of single-cycle processors in some hobby CPU projects (e.g. built with discrete components like DIP-packaged TTL logic ICs) and in “Turning-complete” games such as Minecraft/Factorio, where people wish to have managable amount of work to build a cool proof-of-concept computer.
Therefore, researchers and engineers have come up with numerous ways to get around this limitation and largely improved the throughput by instruction-level parallelism. One of the greatest technique that is seen on almost every chips nowadays is instruction pipelining. The high-level idea though, is simple and intuitive: we can divide the flow of that “giant” computation logic into several stages and try to process each instruction as in a car factory with an assembly pipeline. Each stage has its own sequential logic, so the clock cycle time only needs to accommodate the longest stage in the pipeline, instead of the entire pipeline. Therefore, for a given number of stages, the ideal case is we wisely divide the task so that all stages have similar amount of time for their combinational logic (similar depth). This technique is much more scalable than the single-cycle design, as the designer can choose to use more stages in the pipeline to account for more complex logic required for the target ISA. For example, an Intel Skylake CPU (whose ISA is x86-64) has around 14 stages whereas an ARM Cortex-A77 (whose ISA is ARM64) has 13.
In this mriscv project, we use a classic 5-stage pipeline design that divides
the computation into the following stages:
instruction fetch (IF)
instruction decode (ID)
execution (EX)
memory access (MEM)
register file write back (WB)
which was once a typical arrangement for a RISC processor (e.g. MIPS). There is only one memory access stage in the pipeline thanks to the simplicity of load/store nature of RISC: there is no instruction that needs to both access (load/store) memory and do other computation at the same time, which greately simplifies the pipeline. Overall, each instruction will do one kind of the operations listed below:
math computation with registers, and write back the result to a register;
memory access: load from/store to memory, based on the address provided by registers and the data destination/source is also a register;
control flow: conditionally/unconditionally change the current Program Counter (PC, pointing to the instruction being executed) to other location.
Unlike many other projects, mriscv adopts a clean and modular kind of
organization in its one-file core code (core.sv). The five stages are
implemented in their own modules (fetcher, decoder, executor,
memory and writeback) and put together in core module. This
manifests the data path and control lines that each stage offers and requires.
You can also try to tweak/modify the code of one specific stage for your own
purpose.
Decoder: Parsing an Instruction¶
If you’re familiar with shell/scripting languages like Bash, Python or Javascript, you must have heard of the term “interpreter”. Likewise, a processor is “merely” a hardware-built interpreter that efficiently supports a handful of commands (instructions) by following their syntax (binary format) and semantics (behavior) specified by the ISA. As the name suggests, an interpreter first needs to “understand” what an instruction is all about, by parsing, or in the term of digital circuits, decoding the given instruction.
Luckily, thanks to the elegant design of RISC-V ISA, the format of instructions
in RV32I is very regular. It tends to use the same structure for similar
instructions and put operands to the same bit portion of the 32-bit word for
most of the instructions. Furthermore, it uses a somewhat hierarchical
approach: with “function” code (funct3, funct7, etc.), variants of the
same base operation can be treated in the same way for some cases and
differently for their own semantics. Sometimes function code is
deliberately not continuous to allow testing some bit of the code to efficiently
tell the special treatment.
In our decoder code, we rename the group of wires according to the bit
fields in a instruction.
wire [6:0] opcode = inst[6:0];
wire [2:0] funct3 = inst[14:12];
wire [11:0] funct12 = inst[31:20];
wire [4:0] rs1 = inst[19:15];
wire [4:0] rs2 = inst[24:20];
wire [4:0] rd = inst[11:7];
wire [31:0] ui = {inst[31:12], 12'b0}; //< load upper immediate
wire [31:0] xxxi = {{20{inst[31]}}, inst[31:20]}; //< sign-extended immediate
wire [20:0] jal_offset = {inst[31], inst[19:12], inst[20], inst[30:21], 1'b0};
wire [11:0] jalr_offset = inst[31:20];
wire [12:0] b_offset = {inst[31], inst[7], inst[30:25], inst[11:8], 1'b0};
wire [11:0] l_offset = inst[31:20];
wire [11:0] s_offset = {inst[31:25], inst[11:7]};
// ... (see core.sv for the complete content)
RISC-V instructions usually uses two operand registers (rs1, rs2) and
one destination register (rd). One of the main task the decoder has to do
here is to store the current values of operands to an stage-end register by the
end of the cycle:
wire [31:0] op1 = (ctrl_forward_valid_exec && rs1 == ctrl_forward_rd_exec) ? forward_data_exec:
(ctrl_forward_valid_mem && rs1 == ctrl_forward_rd_mem) ? forward_data_mem:
reg_rdata1;
wire [31:0] op2 = (ctrl_forward_valid_exec && rs2 == ctrl_forward_rd_exec) ? forward_data_exec:
(ctrl_forward_valid_mem && rs2 == ctrl_forward_rd_mem) ? forward_data_mem:
reg_rdata2;
The combinational logic for op1 seems a bit more complex than imagined, due to the need for forwarding
that we’ll later get to. For now, let’s ignore these wires/registers with “forward” in their names, so
the actual logic here is:
wire [31:0] op1 = reg_rdata1;
wire [31:0] op2 = reg_rdata2;
Here, reg_rdata1 and reg_rdata2 are the output signals from the
register file (pins from a register_file module instance) that keeps
flip-flops for all 32 standard RV32I registers. As part of the combinational
logic, the “addresses” (0-31) of the registers we’d like to access are wired to
rs1 and rs2:
// wire to read from register file
assign reg_raddr1 = rs1;
assign reg_raddr2 = rs2;
The register file is implemented in its own SystemVerilog module, whose interface is:
module register_file(
input [4:0] raddr1,
input [4:0] raddr2,
output [31:0] rdata1,
output [31:0] rdata2,
input [4:0] waddr,
input [31:0] wdata,
input wen, //< write enable
input ctrl_clk //< clock
);
In the core module, decoder’s pin reg_raddr1 is wired to raddr1 and
reg_rdata1 is wired to rdata1. The same is for the other operand.
Another important thing the decoder needs to do, according to the design in this project, is to calculate whether there is transfer of the control flow:
// set jump signal for control transfer instructions
assign ctrl_pc_jump_target =
opcode == `JAL ? pc + $signed({{11{jal_offset[20]}}, jal_offset}) :
opcode == `JALR ? op1 + $signed({{20{jalr_offset[11]}}, jalr_offset}) :
opcode == `BXX ? pc + $signed({{19{b_offset[12]}}, b_offset}) : 'bx;
assign ctrl_jump = (!ctrl_skip_next_reg) &&
(opcode == `JAL ? 1 :
opcode == `JALR ? 1 :
opcode == `BXX ?
(funct3[2:1] == 0 ? ((op1 == op2) ^ (funct3[0])) : // BEQ & BNE
(funct3[1] == 0 ?
(($signed(op1) < $signed(op2)) ^ (funct3[0])) : // BLT & BGE
((op1 < op2) ^ (funct3[0])))) : // BLTU & BGEU
0);
The shown combinational logics implements the control signal that determines
whether the processor should move its program counter to a different location
other than the next instruction (PC + 4). ctrl_jump signals 1 if the
processor needs to “jump” to other places, which could be caused by branching
(e.g. BNE), or function calls (e.g. JAL). These control signals will
connect to the logic that fetches the instruction and advances the PC. We’ll
revisit this part later.
Finally, at the end of each cycle, the decoder should already prepare the
decoded information of the instruction, which is stored in SystemVerilog
registers (logic is the same as reg in this context, essentially flip-flops) so they can be used as the inputs in the next cycle of
the subsequent stage:
// ...
output logic [31:0] op1_reg, // op1 for ALU
output logic [31:0] op2_reg, // op2 for ALU
output logic [4:0] rd_reg, // destination general register for writeback
// ...
output logic [31:0] tmp_reg, // keeps some additional value that skips ALU
output logic [31:0] pc_reg, // pass on the instruction address
// ...
output logic [2:0] ctrl_alu_func_reg, // ALU function selection
output logic ctrl_alu_sign_ext_reg, // ALU sign extension flag
output logic ctrl_nop_reg, // if the current instruction should be treated as a no-op
output logic ctrl_wb_reg, // if the instruction needs to write back to a register (use rd_reg in WB stage)
// ...
output logic [4:0] ctrl_mem_reg, // if the instruction needs to access memory (MEM stage)
output [31:0] ctrl_pc_jump_target, // PC target (only valid if ctrl_jump = 1)
output ctrl_jump, // if there is a (non-trap) control flow transfer
// ...
// (see core.sv for the complete implementation)
// (here we just show one logic path that could prepare the value
// for `op1_reg`)
`XXXI: begin
op1_reg <= op1;
op2_reg <= xxxi;
exc_reg <= exc;
ctrl_alu_func_reg <= funct3;
ctrl_alu_sign_ext_reg <= (funct3 == `FSRX) && inst[30];
ctrl_wb_reg <= 1;
ctrl_wb_csr_reg <= 0;
ctrl_mem_reg <= 0;
end
// ...
Executor: All About “Computing”¶
The executor mostly consists of an ALU (and a multiplier/divider if RISC-V “M”
extension needs to be supported). As a simple implementation, here we just use
a multi-way mux to select the calculation by
ctrl_alu_func from last decoder stage, for the given operands:
// ...
wire [31:0] res = ctrl_alu_func == `FADD ? (ctrl_alu_sign_ext ? op1 - op2 : op1 + op2) :
ctrl_alu_func == `FSLT ? ($signed(op1) < $signed(op2) ? 1 : 0) :
ctrl_alu_func == `FSLTU ? (op1 < op2 ? 1 : 0) :
ctrl_alu_func == `FXOR ? (op1 ^ op2) :
ctrl_alu_func == `FOR ? (op1 | op2) :
ctrl_alu_func == `FAND ? (op1 & op2) :
ctrl_alu_func == `FSLL ? (op1 << op2[4:0]) :
ctrl_alu_func == `FSRX ? (ctrl_alu_sign_ext ? $signed(op1) >> op2[4:0] : op1 >> op2[4:0]) : 'bx;
// ...
For the purpose of this project, we can just use the built-in arithmetic and logic operations provided by SystemVerilog, which can be reasonably synthesized for practical use, to support the base instruction set (“I”). For “M” extension, some hand-crafted RTL implementation of the multiplier may be desirable, and one can optimize the different paths of the mux to reduce the latency in the overall circuitry, which isn’t the focus of this project. Readers who are interested in this part can try to plug in their own implementations to this module for these calculations easily.
Finally, as in any other stages, the execution result is stored to a stage register and some other registers that skip this stage are passed on, by the end of each cycle:
// ...
res_reg <= res;
rd_reg <= rd;
// ...
tmp_reg <= tmp;
pc_reg <= pc;
exc_reg <= exc;
ctrl_wb_reg <= ctrl_wb;
// ...
ctrl_mem_reg <= ctrl_mem;
// ...
Fetcher: Automation and Loop¶
So far we know how to decode and execute the instructions, but the processor
still does not automate its work cycles. Like a machine gun, it needs to
automatically feeds in the next instruction to be decoded when last instruction
gets through the decoder, so another round of decoding can happen
when the execution stage continues to work on the decoded instruction. In our code,
a fetching phase, implemented by the fetcher module serves as the portal
to the processor pipeline and fetches the correct instruction from the instruction cache (“i-cache”).
We deliberately abstract away the hierarchy of cache and memory in mrisv, as a modern
processor usually only directly talks to its L1-cache, whose minimal interface is captured
by our core implementation:
// ...
// i-cache communication
output [31:0] icache_addr,
// request flag, having the level of 1 will trigger a request
// of 4-byte data at the address given by `icache_addr` when
// the i-cache is in `idle` state, and it should enter `pending`
// state in the *next* cycle, which ignores the inputs from the
// processor and prepare the data in `icache_data`
output icache_req,
input [31:0] icache_data,
// ready flag, should be set to 1 when the i-cache is in
// `pending` state and has stabilized the valid value in
// `icache_data`. Then it should go back to `idle` in the *next*
// cycle. Whenever the i-cache is in `idle` state, it sets
// `icache_rdy` to 0.
input icache_rdy,
// ...
Here, icache_addr indicates the physical address of the in-memory word
(32-bit integer) the processor wants to fetch next. icache_req flag is
maintained at 1 (level-triggered) if a read is requested. When the request flag
is 1 and the i-cache is in idle, it enters pending state in the next
cycle. When the word data is stable and ready in icache_data wires,
i-cache sets icache_rdy to 1. Then it goes back to idle state in the
next cycle. Whenever the i-cache is in idle state, it maintains icache_rdy
at 0. Thus, it takes at least 1 cycle and may take more cycles to finish
fetching, and our processor accounts for this correctly. The diagram
below shows four continuous reads where each takes 1 cycle, followed by a single read
that takes 3 cycles:

To make the entire SoC design runs on
FPGA, you need to plug in their own cache implementation and memory
controller interface (e.g. some DDR IP core generated by commercial tools such as
Xilinx Vivado) for the i-cache, according to this simple interface. While the
cache interface allows flexibility in interesting use cases, in this repo, we
just emulate i-cache with a few lines of code in sim.cpp to demonstrate the
usage and keep our code base minimal and clean (we also use the same implementation
for d-cache that is soon discussed). In our cache/memory simulation, it by default
has a latency of 1 cycle for all access, whereas one can add in extra latency to
simulate more realistic memory access, by calling the
schedule_next_icache_rdy() (or schedule_next_dcache_rdy() for d-cache)
method of the SimulatedRAM object.
To automate the program counter correctly, fetcher uses a mux to consider
the following three cases:
normal advances of PC: PC + 4 (as each instruction is 4-byte word in RV32I);
control flow transfers by some previous instruction:
ctrl_jumpandpc_jump_targetinputs;trap (for processor exceptions or interrupts) handling:
ctrl_trapandpc_exc_target.
// ...
wire [31:0] next_pc = ctrl_jump ? pc_jump_target : (pc + 4);
// ...
pc <= ctrl_trap ? pc_exc_target : next_pc;
inst_reg <= icache_data;
pc_reg <= pc;
// ...
Memory Access & Writeback¶
Like single-cycle processors, a pipelined design also needs to finalize the state change at the end of an instruction. There are two kinds of state changes:
internal: the change of general/special registers specified by the ISA
external: the change made to main memory locations, addressed at some byte-level granularity
For RISC-V, the external state change can only be done via memory store instructions. Like instruction cache, there is a dedicated in-processor cache, data cache (“d-cache”) that is used for caching data accessed by the memory loads/stores.
This style of distinguishing the storage of instructions from the data they work on is usually called Havard architecture, whereas von Neumann architecture treats instructions and data the same way (“programs are also data”). For modern computer systems, however, the model is more like a hybrid version of both: most micro-architectures have separate i-cache and d-cache for better performance due to the naturally different access patterns of each kind, while the programs they execute do not have such distinction (both instructions and data are managed in the same, unified memory space).
Our d-cache interface is very similar to i-cache’s:
// ...
output [31:0] dcache_addr,
output [31:0] dcache_wdata,
output [1:0] dcache_ws,
output dcache_req,
output dcache_wr,
input [31:0] dcache_rdata,
input dcache_rdy,
// ...
, with the following differences:
unlike the read-only i-cache, d-cache can be in either read or write state, so
dcache_wris added as the flag anddcache_wdatais added as the value for writes;although all instructions are of the same length, RV32I allows manipulating data with different widths (bytes, half-words and words), so
dcache_wsis required to indicate the width: 0 for bytes, 1 for half-words and 2 for words.
The operational logic for d-cache is similar to that for i-cache. It is also a request-based protocol and the data are placed in the lower bits for sizes smaller than a word.
The result after memory stage is either the passed-on value from execution stage, or the value just loaded from the memory:
// ...
wire [31:0] res_mem =
dcache_ws == 2'b00 ? {{24{sgn ? rdata[7] : 1'b0}}, rdata[7:0]} : // LB/LBU
dcache_ws == 2'b01 ? {{16{sgn ? rdata[15] : 1'b0}}, rdata[15:0]} : // LH/LHU
rdata; // LW
wire [31:0] res = (ctrl_mem[1:0] == 2'b10) ? res_mem : res_alu;
// ...
At last, writeback stage is fairly simple in its logic, as most of it has
already been taken care of in register_file module. It just wires the result
to the destination register:
// ...
assign reg_waddr = rd;
assign reg_wdata = res;
assign reg_wen = valid && ctrl_wb;
// ... (the rest of the code in core.sv is about handling
// CSR/traps at the end of the pipeline)
Hazards: Stalls, Bubbles and Forwarding¶
Putting all stages together, we have a pipeline like this:
[fetcher] => [decoder] => [executor] => [memory] => [writeback]
regs regs regs regs
+cycles: 1 2 3 4 5
Ideally, the automation seems to work, if we inject independent instructions from the left, and each stage takes exactly 1 cycle to complete. By these two assumptions, in each clock cycle, each stage will process exactly one instruction, send it over to the next stage and it will take exactly 5 cycles for one instruction to finish the entire pipeline.
Unfortunately, neither assumptions are always true:
instructions that are still in the pipeline can be mutually dependent. For example, a load instruction can write to register
x1whose value is immediately used in a subsequent operation likeaddi x2, x1, 1;each stage may take more than one cycle to complete. For example, both
fetcherandmemorystage can be stalled by cache misses, which waits for the memory to load/store the data. Memory access is several orders of magnitude slower than cache (e.g. dozen to hundred times) and cache could be hierarchical (an L1 cache miss causes an access to L2 cache, which cannot be done within a single cycle);control flow transfer (or traps) can change the normal advancing behavior of PC and suddenly divert it to some random location in the program, which cannot be immediately predicted before fetching the next instruction. So in our design, when the decoder finds out such change to PC, it is already too late.
We call these anomalies that violate the regular progress in the pipeline and potentially generate incorrect results hazards. The issue caused by data dependency is data hazards. Our design is in-order where instructions are pipelined respecting their natural order in the program (instead of being reordered in those out-of-order implementations such as scoreboard or Tomasulo), the typical data hazard for us is “read after write” (RAW, we don’t have WAR or WAW). An example for RAW was given in the first point of the above list. The second point could also be viewed as a kind of data hazards. Moreover, our processor is scalar (single stream of instructions and data), thus it does not have structural hazards, because there are always sufficient hardware resources for each stage to process data (there can’t be multiple instructions trying to multiplex the same structure, such as the ALU, as in some superscalar processors). We do have control hazards as noted by the third point.
To get over with them, we use three classic techniques to tackle with the hazards:
stalls: to generalize the idea and make our implementation clean, we allow each stage in the pipeline to raise a “stall signal”, which will temporarily pause the progress before a stage which is also frozen;
bubbles: to invalidate the instructions that should not have been injected into the pipeline due to the change of control flow, we mark the instructions in earlier stages effectively as “no-ops” (similar to the handling of a NOP instruction);
forwarding: to account for RAW, we forward the results from earlier instructions that are still in the pipeline to later ones by adding a mux to “shortcuts”, before the results are actually written back to the register file.
For each stage, we have a stall signal input and output:
// ...
// whether this stage should be stalled
// this is determined both by `ctrl_fetcher_stall` (directly)
// and whether the subsequent stages are stalled (indirectly)
input ctrl_stall,
// whether the next sage should be stalled:
// - yes: do *not* inject bubble to the input of next stage
// - no: inject a bubble to the next stage
input ctrl_next_stage_stall,
// ...
// whether this stage has a hazard that requires
// stalling itself and its previous stages.
output ctrl_fetcher_stall
// ...
Note that we need to know whether the next stage is also stalled:
ctrl_next_stage_stall wire is the ctrl_stall input used by the next
stage, because for any two adjacent stages, if the current stage stalls:
the next stage is not stalled, we need to ensure the current stage still produces something valid, like a bubble at the end of this cycle, otherwise some stale register values could still persist and there will be a “ghost” instruction used by the next stage;
the next stage is also stalled, then no bubble is need.
It is simply done by the following check in all stages:
// ...
if (!ctrl_next_stage_stall) // insert a bubble
ctrl_nop_reg <= 1;
// ...
Overall, the stall signal ctrl_stall for all stages can be calculated in an
organized way:
// ...
wire ctrl_fetcher_stall_in = ctrl_fetcher_stall ||
ctrl_decoder_stall ||
ctrl_executor_stall ||
ctrl_mem_stall ||
ctrl_writeback_stall ||
ctrl_wfi_stall;
wire ctrl_decoder_stall_in = ctrl_decoder_stall ||
ctrl_fetcher_stall || // because jumps could change PC
ctrl_executor_stall ||
ctrl_mem_stall ||
ctrl_writeback_stall ||
ctrl_wfi_stall;
wire ctrl_executor_stall_in = ctrl_executor_stall ||
ctrl_mem_stall ||
ctrl_writeback_stall ||
ctrl_wfi_stall;
wire ctrl_mem_stall_in = ctrl_mem_stall ||
ctrl_writeback_stall ||
ctrl_wfi_stall;
wire ctrl_wb_stall_in = ctrl_writeback_stall ||
ctrl_wfi_stall;
// ...
In addition to the bubbles generated by stalls, decoder is the one other place that can
generate bubbles, when it hits a transfer of control flow. Due to its limited scenarios, we can
use an internal register in decoder module to indicate whether it should skip the instruction
that immediately comes after the current one:
// ...
logic ctrl_skip_next_reg;
// ...
wire is_nop = ctrl_nop ||
ctrl_skip_next_reg ||
ctrl_trap ||
(opcode == `XXXI && inst[31:7] == 0) ||
opcode == `FEN;
// ...
if (ctrl_reset) begin
ctrl_skip_next_reg <= 0;
ctrl_nop_reg <= 1;
end else if (!ctrl_stall) begin
// ...
ctrl_skip_next_reg <= ctrl_jump;
// ...
ctrl_skip_next_reg <= ctrl_trap;
Thus in our pipeline, a transfer of control flow (or an interrupt) will create exactly one bubble (an exception, however, due to its synchronous nature, will empty the entire pipeline as discussed later). It is encouraged for you to read more materials about one important optimization that could be added to the code – branch predictor. The pipeline will then suffer from at most one bubble only if the prediction is incorrect.
As for forwarding, we know the entire pipeline so far only has one place to read
general-purpose registers: decoder module, whose decoding reads at most two
registers in just one cycle. Then we should look for all places after this
stage where the value of a register could be changed eventually if the
instruction there finally finishes the rest of the pipeline.
executor: an earlier instruction (1 stage ahead) now in execution could generate a new value to the destination register. We should forwardexecutorresult with bypassing wires (no delay in cycles).memory: an earlier instruction (2 stages ahead) now in its memory stage could be a load instruction that writes the value from cache/memory to the register. Unlike theexecutorcase,memorymay take one or more cycles to finish the load operation, so we may need to stall thedecoderto wait for the register value:// ... assign ctrl_decoder_stall = ctrl_forward_mload_stall && (((opcode == `XXXI || opcode == `XXX || opcode == `LX || opcode == `SX || opcode == `JALR || opcode == `BXX || opcode == `SYS) && ctrl_forward_rd_exec == rs1) || ((opcode == `XXX || opcode == `SX || opcode == `JALR || opcode == `BXX) && ctrl_forward_rd_exec == rs2)); // ...
writeback: an earlier instruction (3 stages ahead) now in itswritebackstage could be writing the same register that is needed bydecoder. The sequential logic inregister_filewill only make the written value of register available in the next cycle, which is 1-cycle late fordecoder. Therefore, we need to allow directly bypassing the extra cycle if the register is read in the same cycle:// ... assign rdata1 = writing && waddr == raddr1 ? wdata : regs[raddr1]; assign rdata2 = writing && waddr == raddr2 ? wdata : regs[raddr2]; // ...
In summary, each forwarding path is a bundle of three kinds of signals:
valid bit (1-bit):
ctrl_forward_valid_execandctrl_forward_valid_mem,forwarded (bypassed) value (32-bit):
forward_data_execandforward_data_mem,destination register (5-bit):
ctrl_forward_rd_execandctrl_forward_rd_mem.
An additional mux is added to each operand (op1 and op2, as shown in the
previous code snippet) to select the forwarded value if it is valid and
also matches the register in question.
When the Execution Gets Interrupted…¶
To make our processor practically “usable”, we need to have some minimum support for exceptions and interrupts. For this, we should consult the second volume of RISC-V official specification: Privileged Architecture. RISC-V names three modes: user, supervisor and machine. An operating system needs to execute its code in supervisor mode to have necessary protections such as virtual memory address translation. For example, Linux kernel requires a support for both supervisor and machine mode for its targeted RISC-V platforms. Since we only plan to run bare-metal applications directly on the processor for the purpose of this project, we only need to support the machine mode and many flags can be configured properly according to the specification, without implementing their unnecessary semantics.
RISC-V uses Control and Status Registers (CSRs) to support these privileged features that more or less change the behavior of the processor’s normal execution. We would like to support the following major CSRs required by a realistic machine-mode processor:
mstatus: status register;misa: ISA register, a must-have CSR as it contains the basic information such as bit width and the supported RISC-V extensions. We just encodeRV32I(32-bit, “I”) in it;mie: interrupt-enable register, a global switch that enables/disables interrupts;mtvec: interrupt vector register, which operates in two modes (determined by the lowest 2 bits):BASEis the value ofmtvecafter replacing the last two bits with 0;“direct” mode:
BASEis the entry point of the interrupt handler (PC is set toBASE);“vectored” mode:
BASEis the base address for an interrupt vector table (PC is set toBASE + 4 * <cause>);
mscratch: scratch register for machine-mode programs to store any temporary values;mepc: exception program counter, which saves the original PC before the trap;mcause: trap cause, where the highest bit indicates whether the trap is an interrupt (=1);mtval: stores the additional information for a trap (not written by our processor);mip: interrupt-pending register, which indicates all active interrupts if the corresponding bit is set;mhartid: Hart ID (for hardware thread support, see the specification), a must-have CSR and always contains 0 in our case;mtime,mtimecmp: hardware timer (current and threshold value to trigger a timer interrupt);msip: software interrupt pending-register, which can be set by a program to trigger a software interrupt.
The last three CSRs (mtime, mtimecmp, msip) are memory-mapped
(discussed in the second part of this tutorial) and thus implemented in memory
stage of core.sv, while the rest are all implemented by csr.sv.
CSRs are similar in behavior to general-purpose registers (x0–x31),
but require more care, because csr* instructions swap or read CSRs
atomically. Fortunately, since they can only be accessed by CSR instructions,
there is no additional data hazards for other non-CSR instructions. We just
need to make sure CSRs are forwarded as for general-purpose registers and only
written back in writeback stage for their atomicity.
There are two kinds of traps in RISC-V:
exceptions are raised internally by the current execution stream due to illegal instructions or context and thus the instruction in question should not be effective when the exception is raised; they are synchronous, meaning the processor should drop the possible state change caused by the instruction and stop executing any further instructions before it is resolved;
interrupts are raised by some events or conditions external to the current execution stream, such as timers, I/O or the running program; they are thus asynchronous and do not necessarily need immediate/precise divergence from the execution (although it is always good to have a “low-latency” interrupt controller that diverts the execution timely), and the execution flow being interrupted is still valid.
With these CSRs, we can now implement the trap logic to handle both exceptions
and interrupts in writeback stage:
change PC of
fetcherfor the next cycle according tomtvec;mark all instructions in previous stages as NOPs (clear the pipeline);
push a special flag to
writebackstage, so it writes back all CSR changes (induced by the exception) in the next cycle.
The stage also has a ctrl_trap output signal that enables the trap handling
in csr module (csr.sv):
it is guaranteed by the pipeline that no read/write is on-going and all previous writes are visible;
the value of
mstatus.MIEis copied intomcause.MPIE, and thenmstatus.MIEis cleared, effectively disabling interrupts;the current pc is copied into the mepc register.
Then, when the program exits a trap by mret instruction, the PC calculation
can be unified like:
// ...
wire is_exc = (!ctrl_nop) && exc != 0;
// ...
wire is_trap = is_exc || ((ctrl_mxie & ctrl_mxip) != 0 && ctrl_mie);
// ...
assign csr_raddr = is_trap ? `CSR_MTVEC : `CSR_MEPC;
// ...
assign ctrl_pc_exc_target = is_trap ? (csr_rdata[0] ? (mtvec_base + {26'b0, cause, 2'b0}) : mtvec_base) :
(csr_rdata + 4);
We also signal both ctrl_trap = 1 and ctrl_mret = 1 to csr:
csr csr_reg(
// ...
.ctrl_trap(ctrl_trap),
// ...
.ctrl_mret((!ctrl_nop_mem_o) && ctrl_mret_mem_o),
// ...
);
, so that csr recovers the required CSRs by
set
mstatus.mietomstatus.mpie, which restores the interrupt-enable flagclear
mstatus.mpie
Overall, our processor supports all standard interrupts:
timer interrupts
software interrupts
external interrupts
The external interrupts are level-triggered by the irq pin to the processor:
module core (
input clock,
input reset,
input irq,
// ...
For a more advanced implementation, you should consider adding an “interrupt controller” that supports more sophisticated management of interrupts. For example, interrupts can be buffered so new interrupts that go off during the handling of a trap won’t be dropped or ignored. The RISC-V organization is also working on a specification for a Core-Local Interrupt Controller (CLIC).
Emulate a Realistic SoC environment¶
Ok, now we have a RISC-V processor core implemented in synthesizable SystemVerilog. But it is still just an RTL design that takes the following pins to operate normally:
module core (
input clock,
input reset,
input irq,
// i-cache communication
output [31:0] icache_addr,
output icache_req,
input [31:0] icache_data,
input icache_rdy,
// d-cache communication
output [31:0] dcache_addr,
output [31:0] dcache_wdata,
output [1:0] dcache_ws,
output dcache_req,
output dcache_wr,
input [31:0] dcache_rdata,
input dcache_rdy
);
There are many possible ways to use the implementation. You can interface with
some existing cache implementation for i-cache/d-cache and then design
some wrapping peripheral circuits to signal clock, reset and irq
pin (could be grounded if no external interrupts are needed) properly. It is
also possible to make it “semi-hosted” by some commercial tool so that
cache/memory can be emulated on our host computer, while the core runs entirely on an
FPGA. Here we use sim.cpp as an example, which emulates both the core
logic and peripherals on the computer, with the help of Verilator. Verilator
can compile the SystemVerilog code into standalone C++ code with optimized,
parallelized emulation and thus gives a usable RISC-V computer emulated in
real-time. In this part, we’ll quickly walk through the important ingredients
that make the processor run in a mini setup, ending up with a demo program
that implements a “Snake” (or “Blockade”) video game that is playable with
inputs from the keyboard of the host computer.
No Longer a “Toy”: Starting up a compiled program¶
From the pins required by core module, it is obvious that we need to
emulate the following in our C++ code:
clock: the clock signal for the processor;reset: the reset pulse required upon startup of the processor (to initialize some of its internal registers);irq: the Interrupt Request (IRQ) line to notify the processor of some external I/O; the actual type of interrupt events is usually adhoc to the system; a System-on-Chip (SoC) has its own definitions for inputs from its GPIOs, I2C/SPI or Serial/USB ports, whereas a desktop computer has this part implemented outside the CPU, on the motherboard, managed by its Basic Input/Output System (BIOS) chip (and BIOS also has the duty to initialize the processor when powered on);icache_*: instruction cache, we can just emulate this together withdcache_*;dcache_*: data cache, we can simply emulate the entire memory that allows some configurable delay in response.
In sim.cpp, we implement our entire SoC-like system in a SoC struct:
struct SoC {
std::shared_ptr<Vcore> core;
SimulatedRAM ram;
// ...
};
, where Vcore is the class generated from our core module by Verilator.
Upon an emulation time tick, we emulate the memory clock cycle if the cpu clock is on its rising edge and also evaluate the core processor given its current pin levels:
void tick() {
if (!core->clock)
{
main_time++;
ram.eval_posedge();
}
core->eval();
}
Each clock cycle of the processor is done by two emulation ticks, so we
alternate the core->clock pin between 0 and 1 when we advance the emulation
in the main emulation loop:
// ... (in struct SoC)
void next_tick() {
core->clock = !core->clock;
tick();
}
// ... (in struct SoC)
// emulation main loop
while (!Verilated::gotFinish()) {
soc.next_tick();
// ...
}
A hardware reset is needed before we start the main loop:
// ... (in struct SoC)
void reset() {
core->clock = 0;
core->reset = 1;
tick();
core->clock = 1;
tick();
core->reset = 0;
}
// ... (in struct SoC)
// reset before the main loop
soc.reset();
This gives us a runnable processor. But it is not usable until we load a
program and let it start running from the entry point of the program.
Real-world processors (micro-controllers) define which address the program counter
should be at upon a hardware reset (aka. reset vector), and it is usually in
the specification of the chip product. For example, Intel uses 0xfffffff0
for all its x86 processors when they reset in the “real-mode” (the real-mode is
introduced for backward compatibility to the earliest
8086 chip, of later products). In core.sv, our reset vector is at 0x100000:
`define PC_RESET 32'h00100000
// ...
if (ctrl_reset) begin
`ifdef PIPELINE_DEBUG
$display("[%0t] reset pc", $time);
`endif
pc <= `PC_RESET; // initialize PC
ctrl_nop_reg <= 1;
end else if (!ctrl_stall) begin
// ...
Therefore, we need to load our program into memory at 0x100000. The memory
is emulated by SimulatedRAM class and we provide the emulator a way to load
the content of a binary file to a specific memory location:
void load_image_from_file(FILE *img_file, size_t mem_off, size_t len = 0) {
if (len == 0)
{
auto old = ftell(img_file);
fseek(img_file, 0L, SEEK_END);
len = ftell(img_file);
fseek(img_file, old, SEEK_SET);
}
fread(&memory[0] + mem_off, 1, len, img_file);
}
so that it is easy to load and run a program using the emulator:
// run the hello world program
./sim -l apps/hello.bin=0x100000
So far we’ve figured out (and you should read the code in sim.cpp) how to let a processor load and run a program in its “raw” (machine code) form. Although one can write a program with pure machine code and it works in theory, as human beings, we would appreciate writing in a high-level language such as C/Rust, and compile the program down to the binary code (called “firmware”, or “image”) to be more efficient both in terms of our coding and the program’s execution. Let’s figure out how to get a standard gcc compiler (the Rust example is under apps/mriscv-rs, which shares the linker script with the C apps) to do the job for you, which may also help you develop more understanding in hardware/software interface.
There’re mainly three keywords here: toolchain, linkage and startup. Assuming we’re working
on a host computer with x86-64 CPU for this project, we need a compiler that
runs on 64-bit x86 ISA, but outputs programs that run on 32-bit RISC-V processor.
Compiling a program to its binary may need multiple tools (compiler,
linker, binutils) in such a cross-compilation procedure, and the set of necessary
tools is called a toolchain. In our apps/ directory, you’ll find the use of a
RV32I toolchain in Makefile.
GCC_TOOLCHAIN = ./rv32i/
CC = $(GCC_TOOLCHAIN)/bin/riscv32-unknown-elf-gcc
OBJDUMP = $(GCC_TOOLCHAIN)/bin/riscv32-unknown-elf-objdump
OBJCOPY = $(GCC_TOOLCHAIN)/bin/riscv32-unknown-elf-objcopy
To compiler a C program into our targeted platform, we run the cross-compiler:
// ... in apps/Makefile
$(CC) -march=rv32i -mabi=ilp32 -O2 -nostartfiles -Wl,-Tlink.x -g -o $@ startup.s $< mriscv.o
You may have already noticed that there are some options/flags added to the command line. This is because gcc by default compiles programs that run on an operating system such as Linux, whose execution environment is largely different from those bare-metal programs that run directly on the processor (yes, the operating system can also be viewed as a bare-metal program). Typically, we need to do the following for an embedded (bare-metal) environment:
specify the correct architecture feature sets:
rv32i, because we don’t support many other extensions defined by the RISC-V specification. For example, multiplications can be emulated by other arithmetic operations generated by the compiler, so we can still use multiplication in our C code.specify the correct ABI:
ilp32, which defines the integer model (such as the chosen integer forint,unsigned);remove start files and use custom startup code: use
-nostartfilesto remove the “prologue” code the compiler generates (because it is for running on an OS), where themain()function is invoked, and add in our customized implementation to guide the execution flow to the main function correctly: (instartup.s).global _start .text _start: lui sp, 0x220 call main nop nop nop nop nop halt: beq x0, x0, halt
The global
_startsymbol is the entry point that the linker will use to determine where the program should really start from. We also add some NOPs to make it easier for debugging the processor as they clear the pipeline, and let the processor enter an infinite loop (halt) at the end of the program to guard the execution (so it won’t continue into an invalid portion of memory). The startup code also sets up the stack pointer (sp) to the beginning of the stack (we use0x220000, as our RAM is0x200000-0x21ffff, inclusive).configure linkage correctly: because our program runs directly on the processor and accesses physical memory (rather than virtual memory) without an OS, we need to let the linker know how to finally arrange our binary code and how to utilize memory space. We first define the memory layout on our platform (
memory.x):MEMORY { FLASH : ORIGIN = 0x00100000, LENGTH = 1M RAM : ORIGIN = 0x00200000, LENGTH = 32M } // ...
and then the sections in the binary (
link.x):INCLUDE memory.x SECTIONS { . = ORIGIN(FLASH); /* load from the beginning of the flash */ .text : { KEEP(*(.text)) *(.text.startup) } > FLASH .rodata : { *(.rodata) *(.rodata.*) } > FLASH .data : { *(.data) *(.sdata) *(.sbss) } > RAM .note.gnu.build-id : { *(.note.gnu.build-id) } > FLASH /DISCARD/ : {*(*)} }
Here we use
FLASHto represent the space for storing the program code (which is usually in a flash storage, for real-world SoC chips)..textis the section for the code, followed by.rodata(read-only data) and.data(read-write initialized data). With the linker script, the compiled program will start from our reset vector and utilize the available memory space correctly.(optional) link with some helper libraries: mriscv.c implements some helper functions to make development easier (such as
uprintf).
The output file from the compiler/linker, though, is in ELF-format, which is the common format for Linux binaries. The format should not be part of our final image to be loaded on the processor. Thus, we need to extract its “pure” content to have the image which only contains code and necessary data:
// ... in apps/Makefile
$(OBJCOPY) -O binary -j .text -j .rodata -j .data $< $@
Printing to the Console¶
So far, although our processor can run programs, it is somewhat “useless” because we cannot
even get the output from a program. Also for the purpose of debugging, we would
like something similar to printf in our C code (print! in Rust) that can directly output
formatted string to the console. How does an SoC achieve this
realistically, as it doesn’t have a built-in display/keyboard? The short answer is
serial communication (which is tied to the terms like “tty” and “console” for a PC, or an old mainframe server).
Modern micro-controllers support ways to both flash (“program”) the program
into the chip’s ROM, and establish console I/O from the ROM firmware while it is
running. A very pervasive interface is Universal Asynchronous
Receiver-Transmitter (UART). The basic hardware logic is to first serialize
data (a byte) using a shift register and then transmit bits via asynchronous
serial signals. The data received will be reassembled from the shift
register at the recipient back into a byte. On a micro-controller (such as those
common Arm Cortex chips manufactured by STMicroelectronics and RISC-V chips produced by
SiFive, according to the author’s limited knowledge), the UART communication is
done by writing to or reading from some memory-mapped special “registers”.
Unlike the general or CSR registers we use directly as part of the ISA instructions, these
registers can be more viewed as special (word-aligned) memory locations with which one can communicate
to the processor. Because these memory locations are special in their
semantics, one should use the volatile keyword when access them in a C program, to
avoid incorrect optimization by the compiler.
We use a custom, but very typical register interface for emulated UART (only the transmitter, i.e., output) as below:
the UART transmitter register address:
0x1000;when the processor writes to the register: the low 8-bit content of the written word is transmitted from the processor, and will be printed to the emulator’s console;
when the processor reads from the register: the value will be 0 only when the previous transmission is finished.
Therefore, we just need the following code to implement the emulator side:
// ...
const uint32_t uart_txdata_addr = 0x00001000;
// ... (in `eval_posedge()` of `SimulatedRAM`
if (addr == uart_txdata_addr)
{
if (core->dcache_wr)
{
debug("dcache: write uart = %02x\n", addr, data);
putchar((uint8_t)data);
}
else
{
core->dcache_rdata = 0;
debug("dcache: read uart = %02x\n", core->dcache_rdata);
}
}
// ...
, and then we can implement putchar and print functions as part of the
library (mriscv.c) for our programs:
// ...
static uint32_t * volatile const __attribute__ ((used)) UART_TXDATA = (uint32_t *)0x00001000;
// ...
int putchar(int c) {
while ((*UART_TXDATA) >> 31) {}
(*UART_TXDATA) = ((*UART_TXDATA) & ~0xff) | c;
return c;
}
size_t print(const char *s) {
size_t n = strlen(s);
for (unsigned i = 0; i < n; i++)
putchar(s[i]);
return n;
}
Without heap allocation, we can still implement a simplified version of
sprintf — uprintf in our library using a (stack-based) preallocated
array buffer:
// ... (see mriscv.c for the implementation of `int_to_string` and `itoa`)
int uprintf(char *buff, const char *fmt, ...) {
size_t nwrote = 0;
va_list ap;
va_start(ap, fmt);
for (const char *p = fmt; *p != '\0'; p++) {
if (*p == '%') {
p++;
switch (*p) {
case 's':
nwrote += print(va_arg(ap, const char *));
break;
case 'd':
itoa(va_arg(ap, int), buff);
nwrote += print(buff);
break;
case 'u':
int_to_string(va_arg(ap, unsigned), buff, false, false, 10);
nwrote += print(buff);
break;
case 'x':
int_to_string(va_arg(ap, unsigned), buff, false, false, 16);
nwrote += print(buff);
break;
case 'X':
int_to_string(va_arg(ap, unsigned), buff, false, true, 16);
nwrote += print(buff);
break;
case '%':
putchar('%');
nwrote++;
break;
default:
va_end(ap);
return -1;
}
} else {
putchar(*p);
nwrote++;
}
}
va_end(ap);
return nwrote;
}
Then we can write our “hello world” program in C (apps/hello.c):
#include "mriscv.h"
int main() {
char buff[32];
for (int i = -5; i < 5; i++)
uprintf(buff, "Hello, world! %d\n", i);
print(buff);
return 0;
}
which outputs formatted strings correctly:
$ ./sim -l apps/hello.bin=0x100000
Hello, world! -5
Hello, world! -4
Hello, world! -3
Hello, world! -2
Hello, world! -1
Hello, world! 0
Hello, world! 1
Hello, world! 2
Hello, world! 3
Hello, world! 4
We next implement similar functions in Rust. Thanks to Rust’s powerful macro system, one can print formatted strings more ergonomically (a shrinked version of apps/mriscv-rs/examples/hello.rs):
#![no_std]
#![no_main]
extern crate mriscv;
extern crate panic_halt;
use core::fmt::Write;
use mriscv::{uprint, uprintln};
use riscv_rt::entry;
#[entry]
fn main() -> ! {
uprintln!("hello, world! Count from 10:");
for i in { 0..10 }.rev() {
uprintln!("now it is {}...", i);
}
mriscv::wfi_loop();
}
Timer, Keyboard, Video and a Useful Library¶
We would like to introduce more useful library functions before we write something more complex in Rust. In apps/mriscv-rs/src/, there are implementations for:
a way to set the timer by writing to the memory-mapped CSR registers;
uprint!anduprintln!macros;a heap-less, circular queue,
Queue256, based on the heaplessVecprovided byheaplesspackage;a safe, event-driven abstraction for handling timer, software and external interrupts, so an application does not need to define the global interrupt handlers and thus adopts a cleaner way (without
unsafe) to write interrupt-driven logic, implemented with the help ofQueue256;get_framebuffer()for video output.
We use the external interrupt (irq) to signal keyboard inputs are
available, while the actual key code is stored in a memory-mapped register at
0x3000. In the emulator, keyboard events are captured by SDL2 (you need to
build sim with env ENABLE_SDL=1 make to enable this and the video
support).
Finally, we use a VESA-framebuffer-like interface to memory-map the video
framebuffer into 0x10000000–0x1004ffff (320K, RGB222, 640x480, 1 byte per pixel), which
is rendered to the GUI window on the emulator host.
The program can update the framebuffer to render some graphics. An example is to randomly draw colored pixels to the entire frame:
#![no_std]
#![no_main]
extern crate panic_halt;
use rand::Rng;
use rand::SeedableRng;
use riscv_rt::entry;
const INTERVAL: u32 = 0x1000000;
static mut COUNTER: usize = 0;
static mut RNG: Option<rand::rngs::SmallRng> = None;
#[export_name = "MachineTimer"]
fn timer_handler(_trap_frame: &riscv_rt::TrapFrame) {
let fb = mriscv::get_framebuffer();
unsafe {
mriscv::set_timer(INTERVAL);
for i in 0..fb.len() {
COUNTER += 1;
fb[i] = RNG.as_mut().unwrap().gen();
}
}
}
#[entry]
fn main() -> ! {
unsafe {
RNG = Some(rand::rngs::SmallRng::from_seed([0; 16]));
riscv::register::mstatus::set_mie();
mriscv::set_timer(INTERVAL);
}
mriscv::wfi_loop();
}
The frame will be updated every ~16 million cycles (apps/mriscv-rs/examples/video.rs):

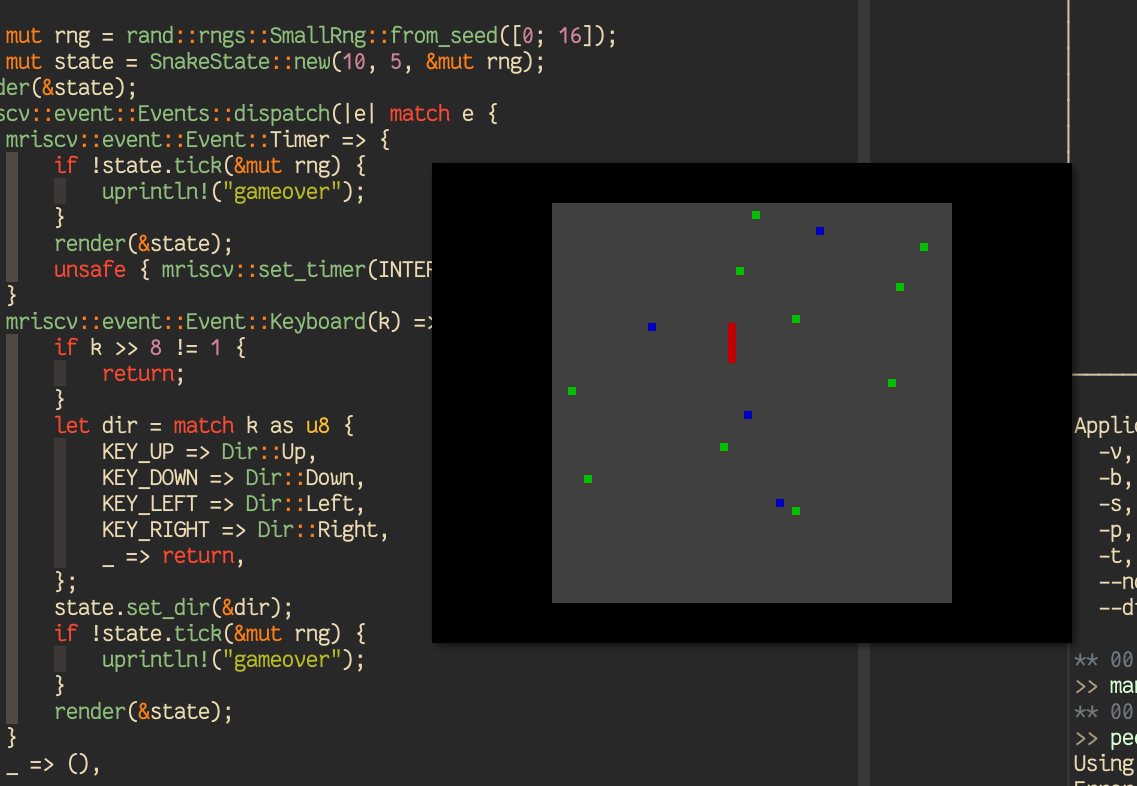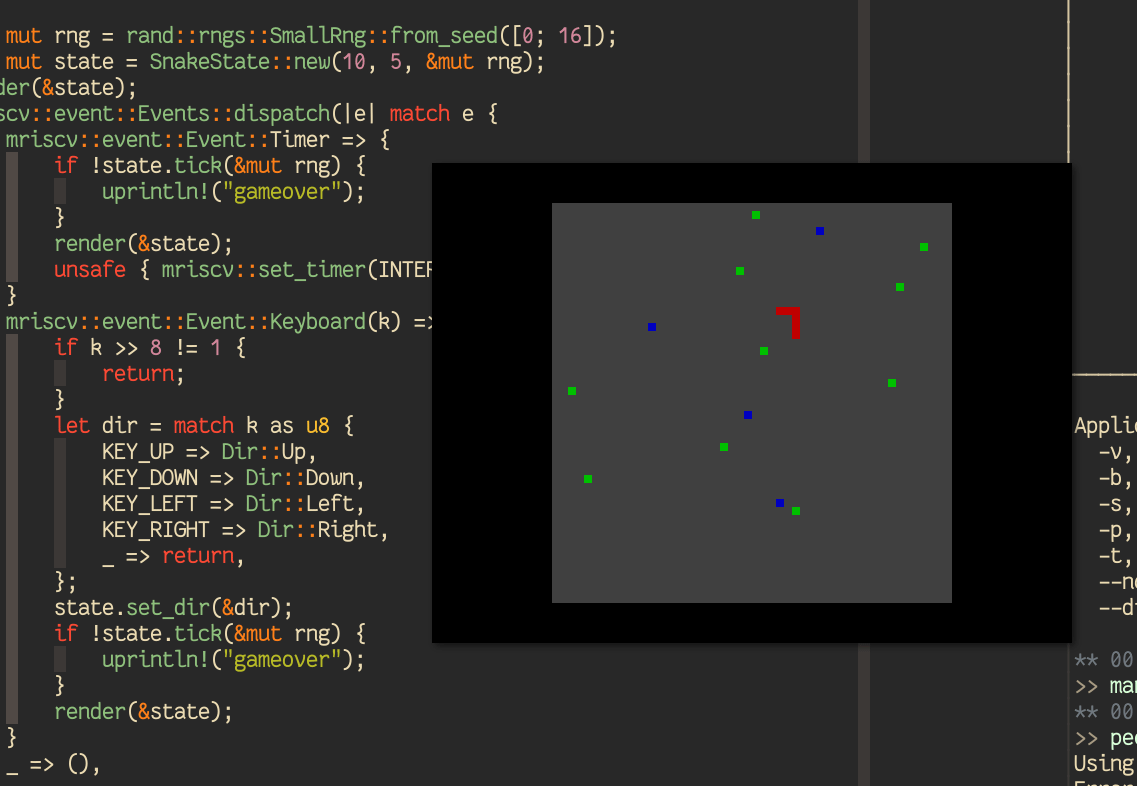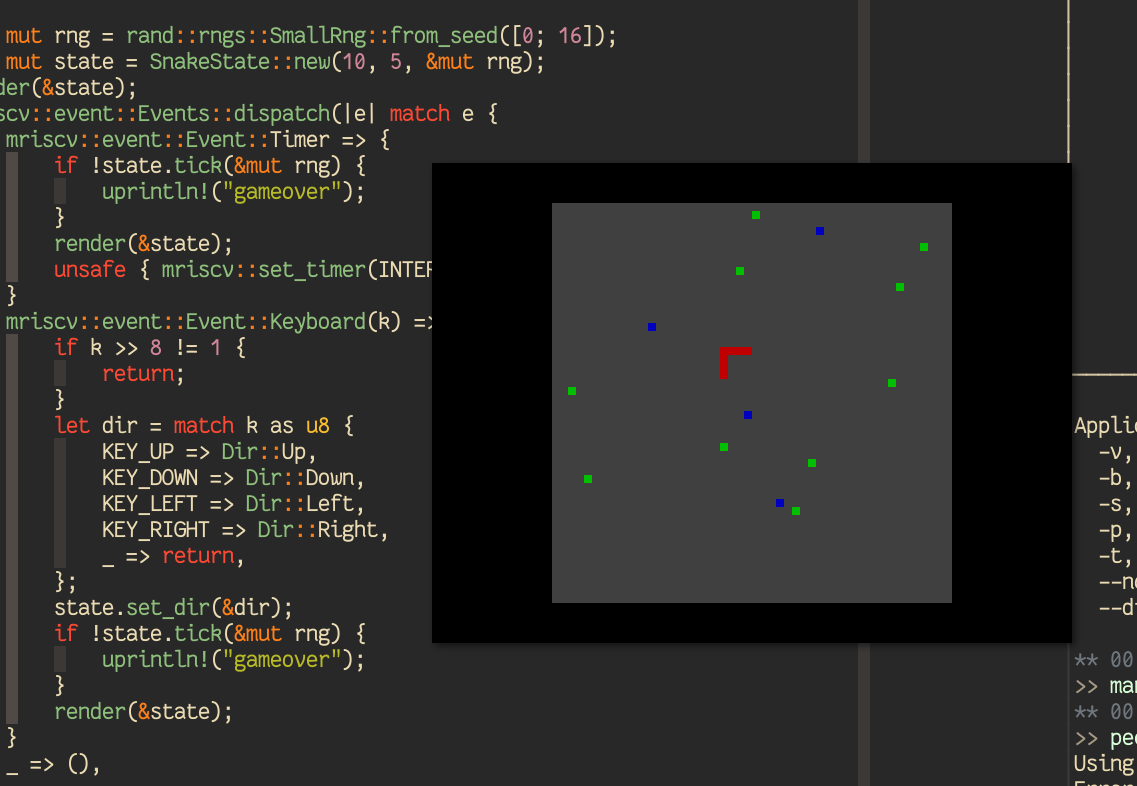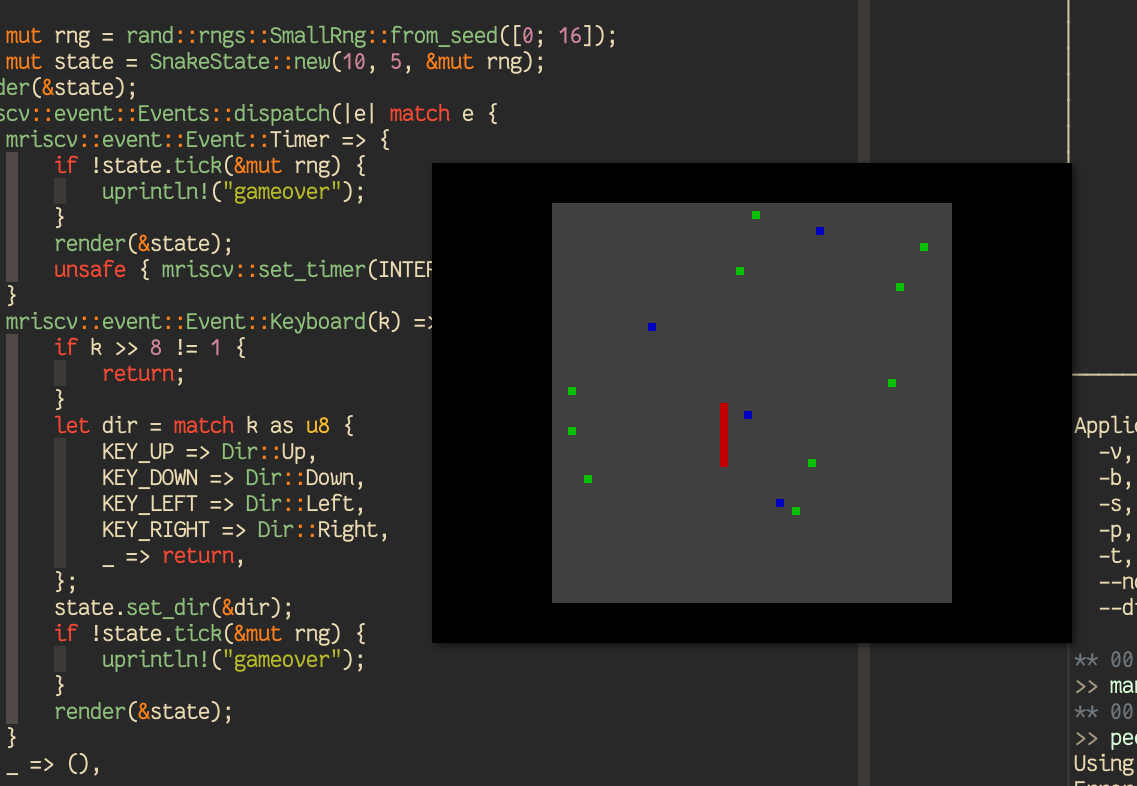
A Snake Game¶
With all these ingredients, to end our journey in this tutorial, we finally put together a Rust game that is similar to “Snake” in apps/mriscv-rs/examples/snake.rs with ~250 lines of code that is nice and clean. It takes up/down/left/right inputs from the keyboard and renders the game play every “second”: